Chat to Your Requirements: My Journey Applying Generative AI (LLM) To Software Requirements
Discover how I applied Large Language Models (LLM) to software requirements, creating a knowledge hub of business logic and copilot for faster development.
Join the DZone community and get the full member experience.
Join For FreeIn the digital age, large enterprises are plagued by a lack of understanding of their legacy systems and processes. Knowledge becomes isolated in silos, scattered among various teams and subject matter experts. This fragmentation contributes significantly to the growth of technical debt, a silent killer that gradually hinders the organization's agility and productivity. At Curiosity Software, we have spent the past five years creating structured requirements (through visual models) and connecting to hundreds of DevOps tools. We believe this puts us in an incredibly advantageous position when implementing Generative AI. The models and DevOps artifacts can act as the central hub of access to data flowing through an organization’s software development landscape.
As part of our mission to combat the prevalent challenges of technical debt and missing knowledge, we embarked on a journey to apply Large Language Models (LLM) to software requirements and business logic. Our goal was to create a knowledge hub for an organization’s software requirements, which can be queried to uncover knowledge and pay off technical debt.
Understanding the Terrain of Large Language Models (LLMs)
Before discussing our experiences and insights, let's set the stage by providing a brief overview of Large Language Models. LLMs, like OpenAI's GPT-4, are capable of understanding and generating human language. They learn from a vast corpus of data, encompassing a wide range of topics and language styles.
These LLMs work on a deep learning model known as a Transformer, which uses layers of self-attention mechanisms (neural networks) to analyze and understand the context within data. During training, they read countless sentences and paragraphs and make predictions on what comes next in a sentence. These predictions are based on what they've read so far:
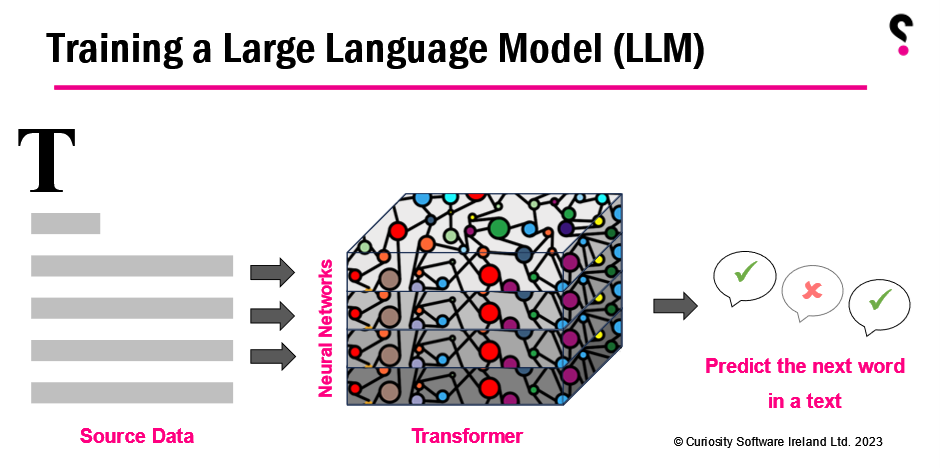
The amazing thing about an LLM is its ability to generate human-like text. This comes when it is trained on a large corpus of data and has a high number of parameters or weights in the model (GPT-4 has hundreds of billions):
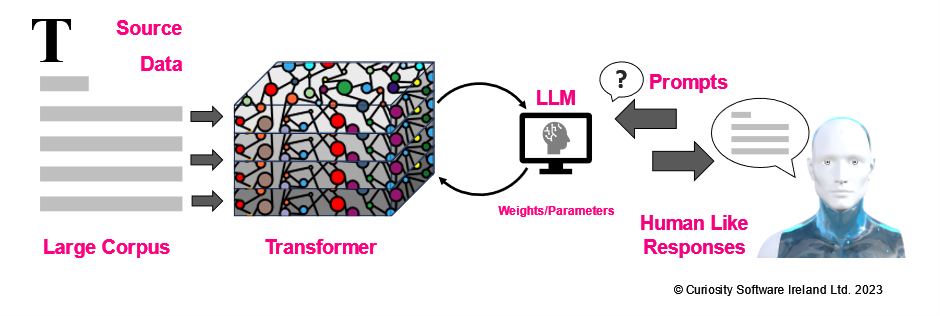 This uncanny ability to respond like a human is attributable not only to the intelligence inherent in the algorithm but also to the discovery that human language may not be as intricate as we first believed.
This uncanny ability to respond like a human is attributable not only to the intelligence inherent in the algorithm but also to the discovery that human language may not be as intricate as we first believed.
By exposing a neural network to sufficient instances of human language, an LLM can discern patterns and respond aptly to inquiries. As the size and quality of data a LLM is trained on increases, the power of a LLM grows exponentially with it.
Structured Data Is Essential to LLM Success
For software organizations today, the ability to leverage LLMs has never seemed closer. There are incredibly compact, specialized models that can run on a local PC and which rival the performance level of GPT-3.5.
Yet, the most important piece of an LLM is not the available tooling; it’s the data that an LLM has been trained on. This is, therefore, also the main obstacle to the successful use of LLMs, as organizations today lack structured data in the software domain.
Software requirements are typically stored in an unstructured textual format and, worse still, are often incomplete, ambiguous, and missing information. The same is true for test cases, which are often stored as lists of textual-based test steps.
Overcoming this structured data issue requires innovation and careful consideration. Techniques like information extraction, natural language understanding, and machine learning can be employed to transform unstructured data into structured data. This process often involves manual human intervention.
An alternative solution to training an LLM is not to try to train it on unstructured textual data. It aims to create structured requirements from the get-go or to convert unstructured data to structured requirements as an intermediary.
This is where modeled requirements can empower the creation of AI-ready requirements for training language models. We can use models to structure and improve existing data, integrating the existing SDLC artifacts with models in a central knowledge hub.
What Is Modeling for Software Requirements?
Model-based testing uses a model of the feature under consideration to generate test cases. These models are usually represented as visual flowcharts, which clearly define the software requirements by depicting the system's behavior, functions, or operations.
By using such models, ambiguity can be reduced, making it easier for both developers and testers to understand the requirements. Moreover, modeling facilitates the automatic generation of test cases, data, and automation. Any changes in the software requirements can be reflected by altering the models, leading to dynamic and updated test assets.
Flowcharts offer a visual method of presenting complex processes in a simple and understandable manner. They show each step as a box or symbol, with arrows between them showing the flow of users and data through the process. This gives a clear, easy-to-follow representation of the process, highlighting the sequence of operations and the decision-making points:
Typically, an organization that is leveraging model-based testing will create a library of reusable models, which can then be connected to build much richer end-to-end scenarios at speed. The process of componentization allows the team to move much faster in creating their test assets but also react to change in a streamlined approach:

Flowcharts Are Structured for LLMs
Flowcharts are inherently structured by nature. When it comes to training Large Language Models, structured data in the form of flowcharts can produce extremely empowering results.
Moreover, flowcharts are ideal for querying because they are intuitive and simple to interpret. The flow of control and decision-making process are clearly depicted, making it easy for the model to predict the next steps in the process.
The ability to infer relationships between the various steps makes flowcharts particularly valuable for both querying and training LLMs. Here is an example of using an LLM to query a simple model. The model below depicts a student checking account application process:
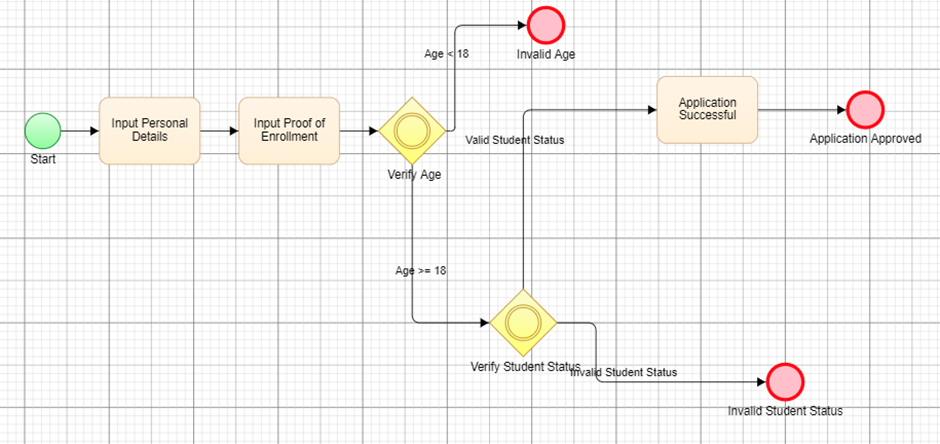
Prompt: How old does a student have to be to get approved for a student checking account?
Response: 18 years or above.
Prompt: How can a student get approved for a student checking account?
Response: To be approved for a student checking account, a student would first need to input their personal details. This would be followed by verifying their age to ensure they are 18 years or older. Once their age is confirmed to be 18 or over, the student must then input proof of enrollment to prove their student status. If all these criteria are met, and the application is successful, the student will be approved for a student checking account.
Conversing With Software Requirements
Given the proven ability of LLMs to query and reason on flowcharts (models) and the range of connectors Curiosity has built into DevOps tools, we sought to apply LLMs to flowcharts and DevOps artifacts. We sought to combine models with data from across disparate DevOps artifacts, creating a central knowledge hub for LLMs.
We have applied and trained LLMs on an array of software requirements (captured from JIRA) and models stored in an organization's Test Modeller workspace. For this project, we have a JIRA project with a series of tasks for a banking application, along with models that have been created for textual-based issues. These models overlay additional structure and complete the requirements, creating the data needed by an LLM:
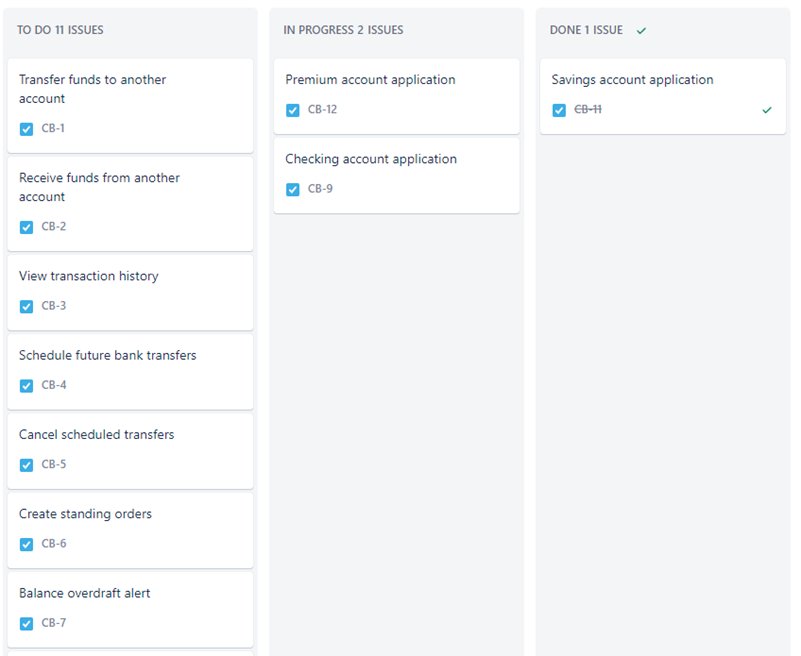
Here is an example ticket:
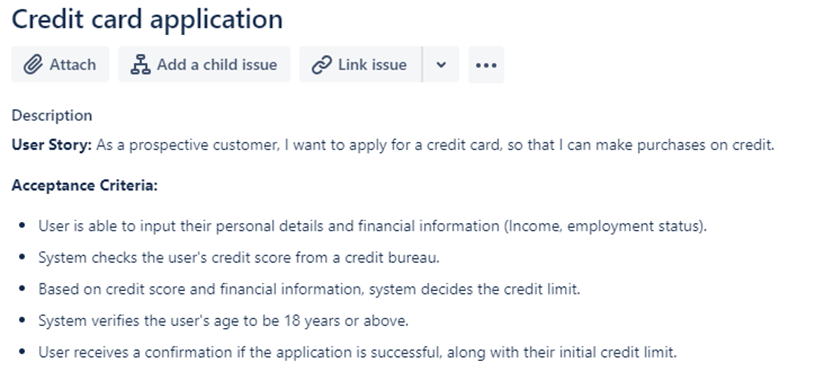
If you compare the “wall of text” user story above to the visual requirement below, you’ll see how much easier the flowchart makes it to understand the logic of applying for a credit card. This is because of the inherent structure and visual nature of a flowchart.
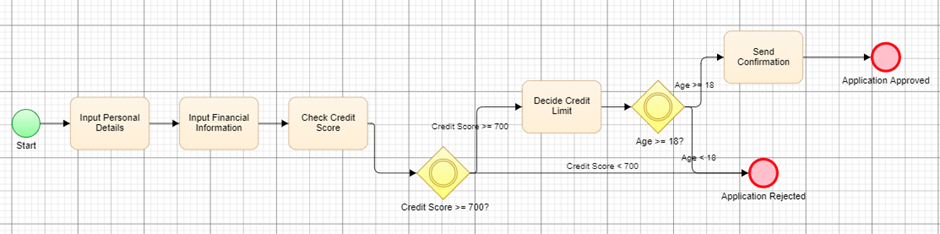
The collection of flowcharts and Jira tickets synchronized in the Test Modeller workspace provides a knowledge hub for the LLM. When queried, the LLM can, therefore, leverage and reason on information stored across otherwise disparate SDLC artifacts, for instance, data stored in multiple Jira tickets.
Let’s look at some examples querying this knowledge hub using an LLM trained on the example banking software requirements and models.
Example 1: Simple Question
Let’s start firstly with a simple question on which we would expect it to perform well. Give me the details of a JIRA ticket, given its identifier.
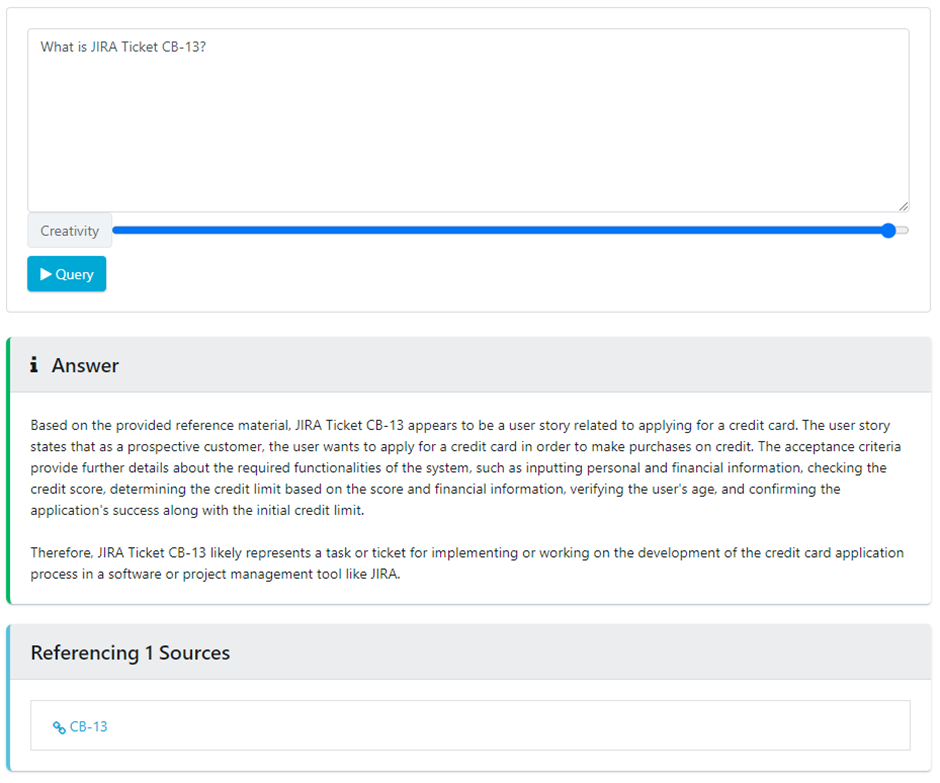
Prompt: What is JIRA Ticket CB-13?
We’ll see if this comes back with a summary of the ticket:
Example 2: Implied Reasoning With a Model
In this example, we’ll go a little bit deeper and ask a question that expects the LLM to understand a flowchart and then deduce an answer from it. Specifically about the credit card application process.
Prompt: What credit score is required to complete a credit card application?
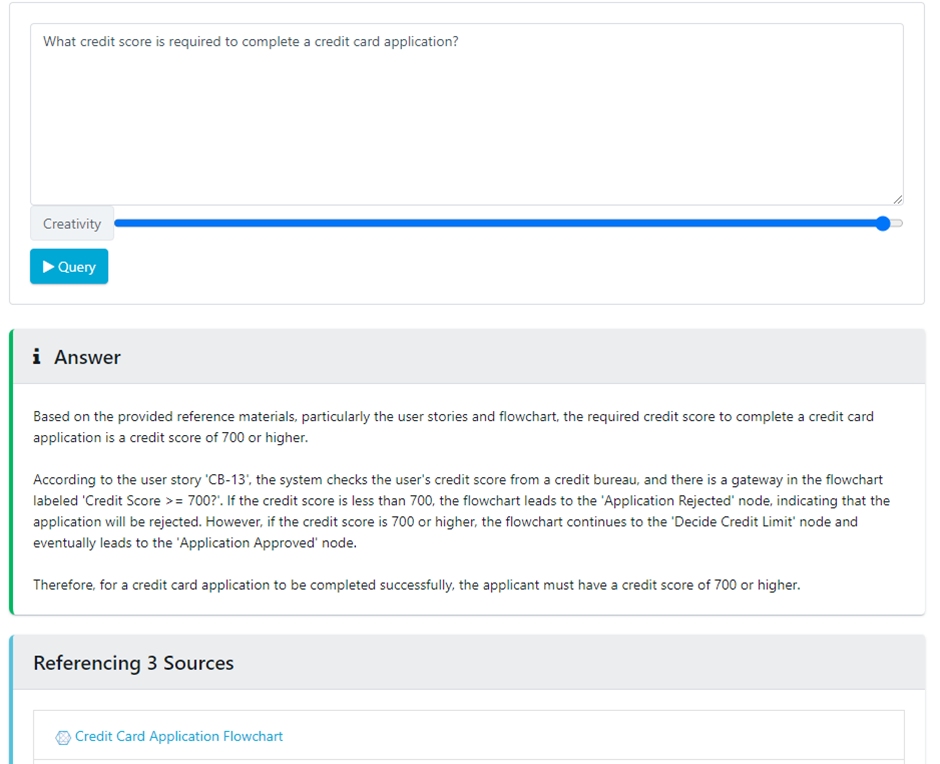
The LLM has captured the flowchart for a credit card application process and interpreted the model. It has then used this interpretation to calculate the required credit score of 700 or above.
Example 3: Implied Reasoning with Models and Requirements
This prompt requires the LLM to interrupt multiple sources of information to answer the question. It looks up a model and also the corresponding requirement.
Prompt: When can a customer apply for a credit card?
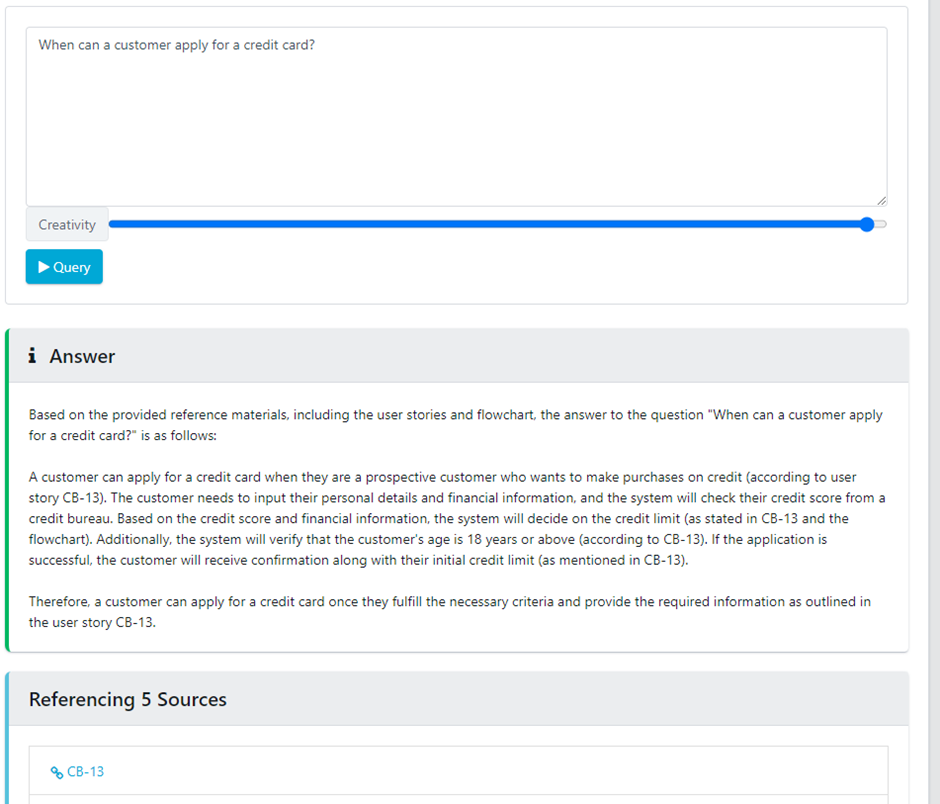
Example 4: Multi-Requirement Reasoning
This prompt requires multiple requirements to be understood and reasoned to answer a cross-requirement query. We’ll see in the response that three user stories are referenced to answer that the products are only available if an individual has a good credit score.
Prompt: What products can I apply for if I have good credit?
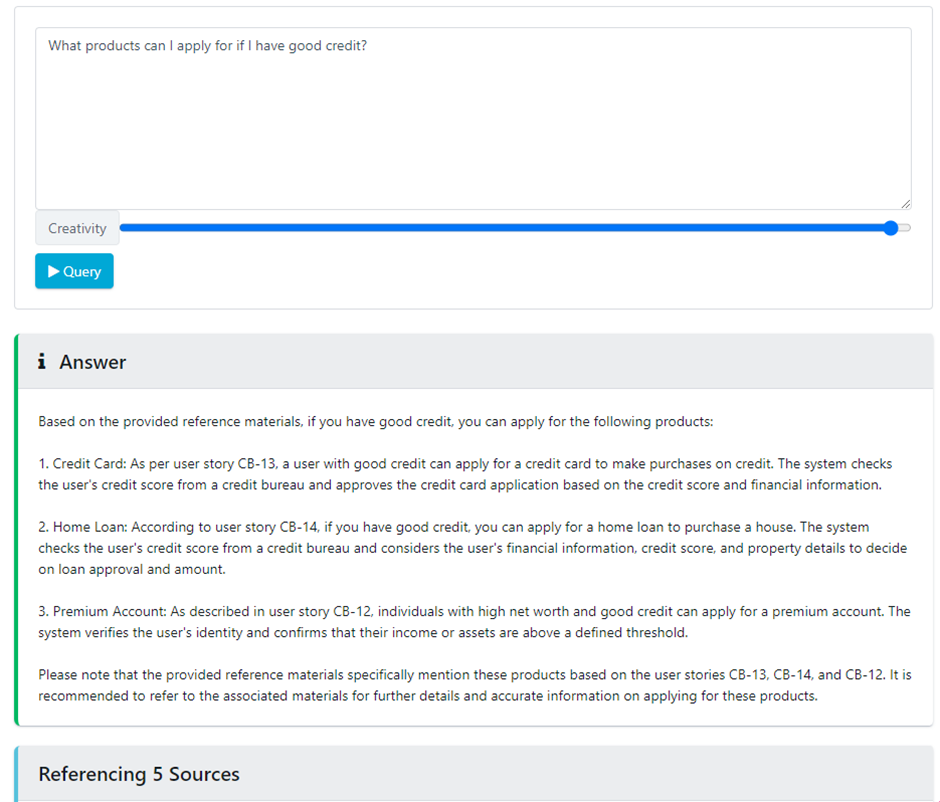
Demo: Using LLMs to Query Structured Flowchart Data
Watch me synchronize information from Jira user stories into a central knowledge hub and run the queries used when writing this article:
Adopt LLMs for Better Software Delivery
Curiosity Software is leveraging Large Language Models (LLMs) such as OpenAI's GPT-4 to better understand and manage software requirements and business logic, with a particular focus on combating technical debt.
Given that LLMs thrive on structured data, model-based testing is the perfect tool for completing and removing ambiguity in unstructured data. The models provide a source of structured business flows, using visual flowcharts to represent software requirements, which in turn provide clarity. At the same time, we can synchronize information from DevOps tools and artifacts in a central knowledge hub.
This approach also enables the automatic generation of test cases, data, and automation. Using these methods, Curiosity Software is actively working on training LLMs on a broad spectrum of software requirements captured from various DevOps tools, which are modeled in an organization's Test Modeller workspace. This creates a co-pilot and dashboards that provide explanations of the whole SDLC when queried while informing decisions around risk, releases, test coverage, compliance, and more:
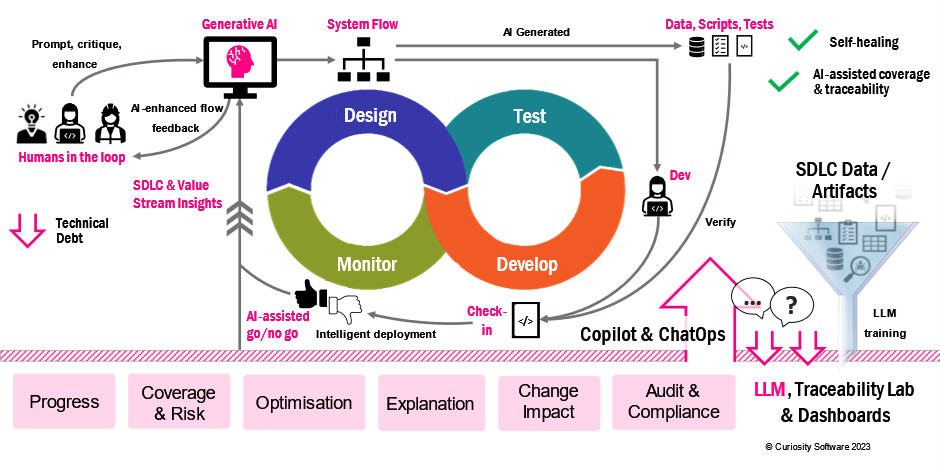
We can even generate models using Generative AI, as described in my last article. This closes the feedback loop. A human can work with a Generative AI to create and iteratively improve models based on data in flowcharts and broader SDLC artifacts. The flows, in turn, provide accurate specifications for developers while generating tests to verify the code they create.
The resultant data from this AI-assisted software design, testing, and development is fed into our central knowledge hub. This updates the LLM, informs future iterations, and avoids technical debt.
This application of AI to software requirements can help improve the efficiency and effectiveness of software development processes, act as a knowledge hub for an organization’s business process, and finally combat technical debt.
Published at DZone with permission of James Walker. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments